| Top Language | Count | Percent of Total |
|---|---|---|
| R | 149 |
46.7%
|
| Python | 73 |
22.9%
|
| null | 42 |
13.2%
|
| Jupyter Notebook | 18 |
5.6%
|
| SAS | 8 |
2.5%
|
| TSQL | 7 |
2.2%
|
| Batchfile | 6 |
1.9%
|
| TeX | 5 |
1.6%
|
| HTML | 4 |
1.3%
|
| Dockerfile | 1 |
0.3%
|
| Java | 1 |
0.3%
|
| JavaScript | 1 |
0.3%
|
| Rebol | 1 |
0.3%
|
| Roff | 1 |
0.3%
|
| Rust | 1 |
0.3%
|
| Shell | 1 |
0.3%
|
Public GitHub Org 
frank aragona
Overview
- Washington DOH GitHub use statistics over time
- NW-PaGe GitHub org details
- Security
- GitHub Pages + Quarto
- Examples
group goals and my goals
NW-PaGe GitHub Org (link)
Goals
- Transparency
- Reproducibility
- Education
- Collaboration
My Goals
- Write the SOPs
- Prevent data leaks
- Explore publishing tools
- Get the ball rolling

Security
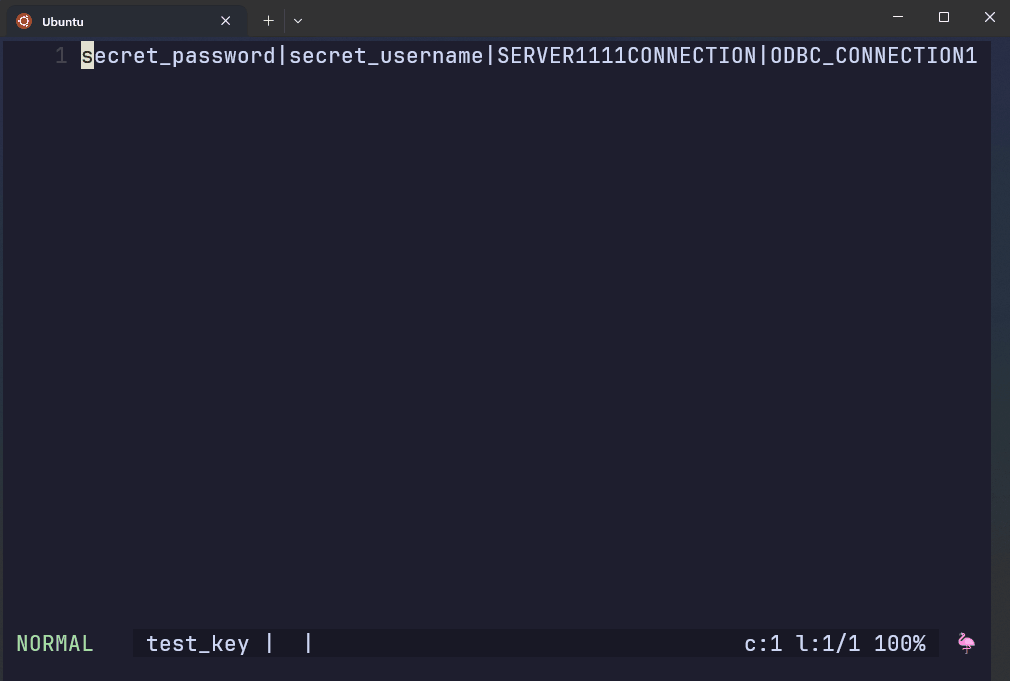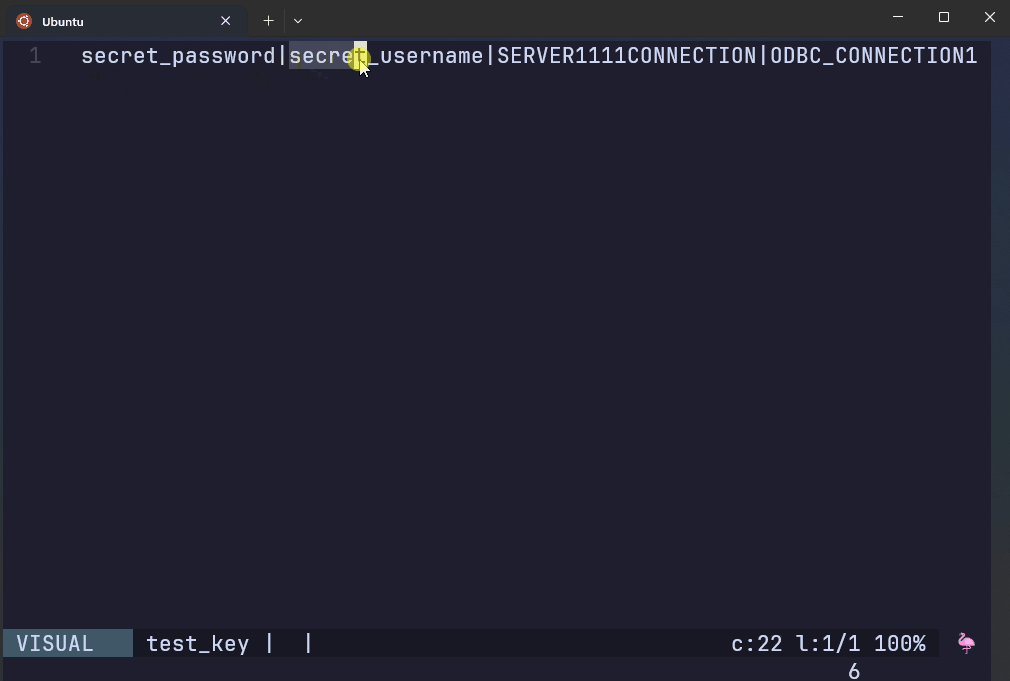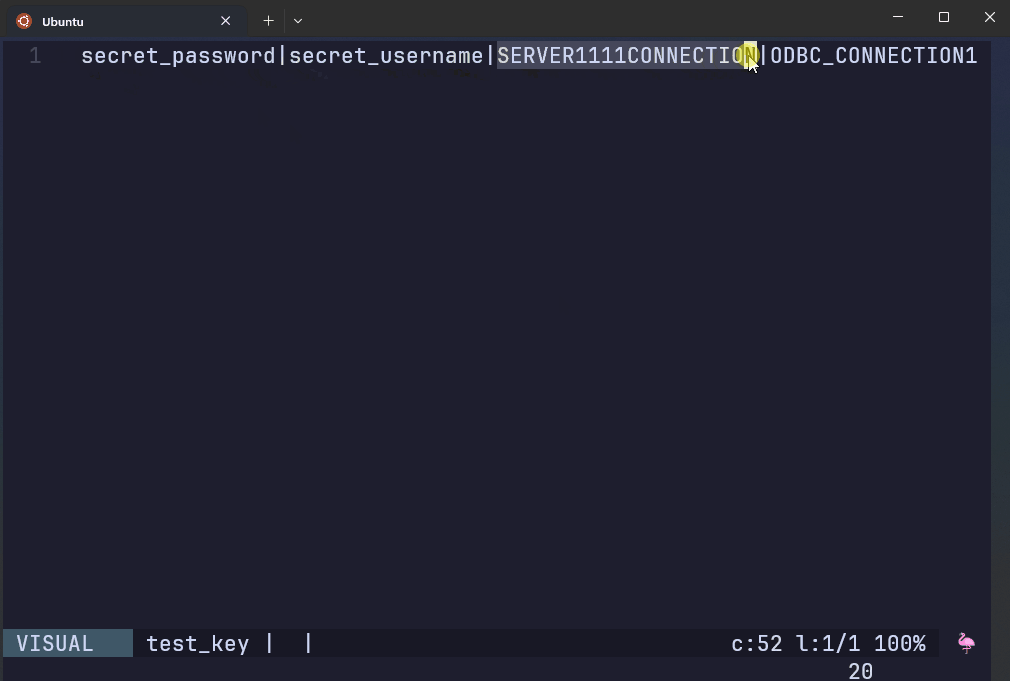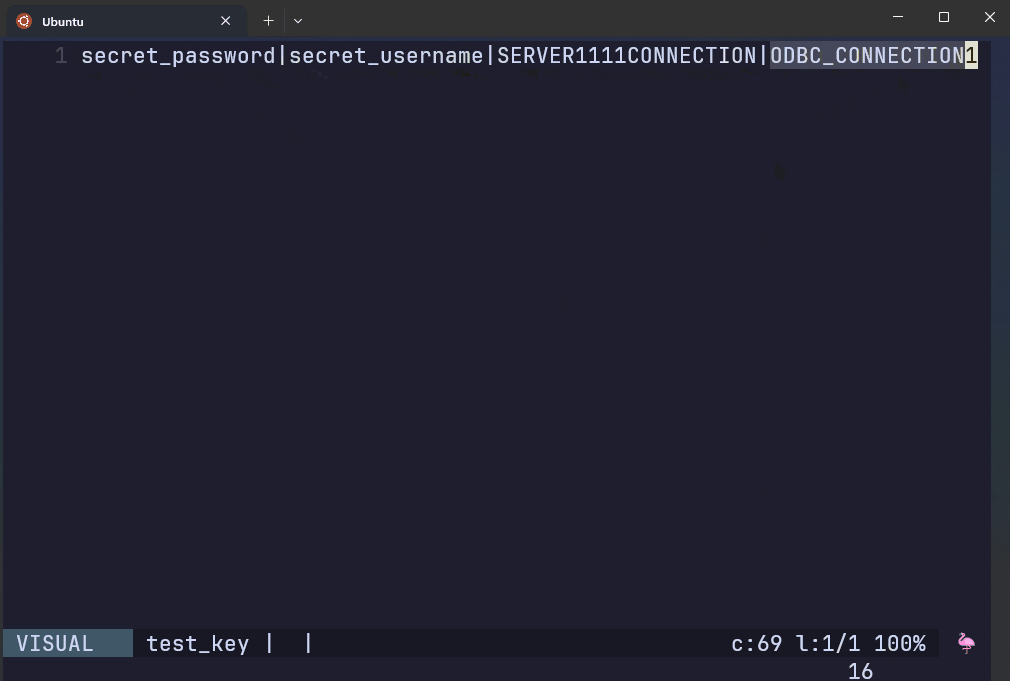
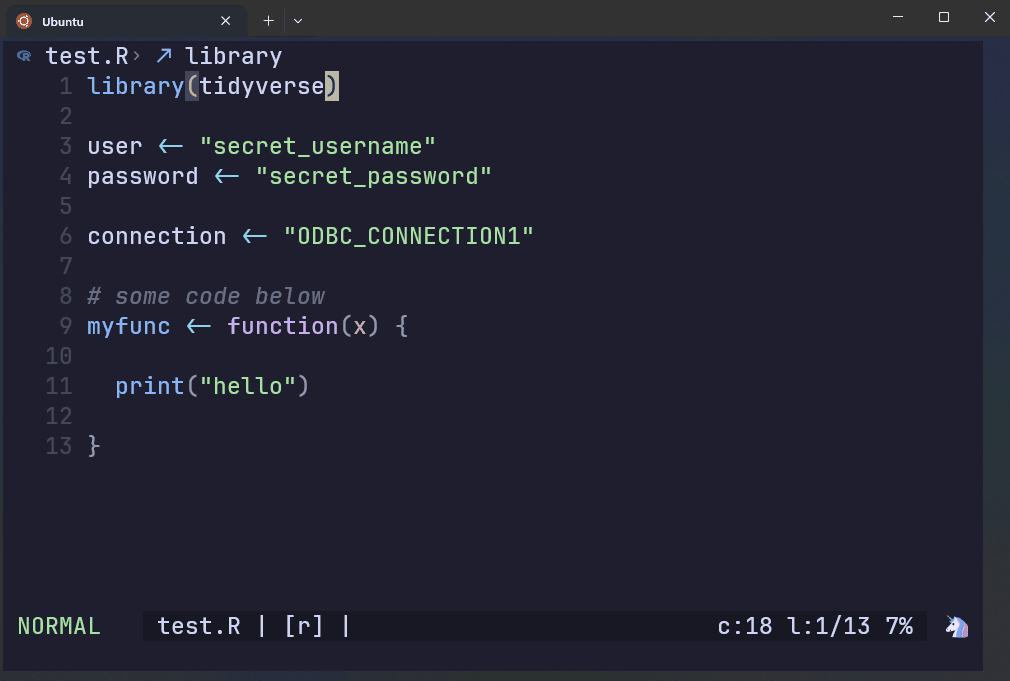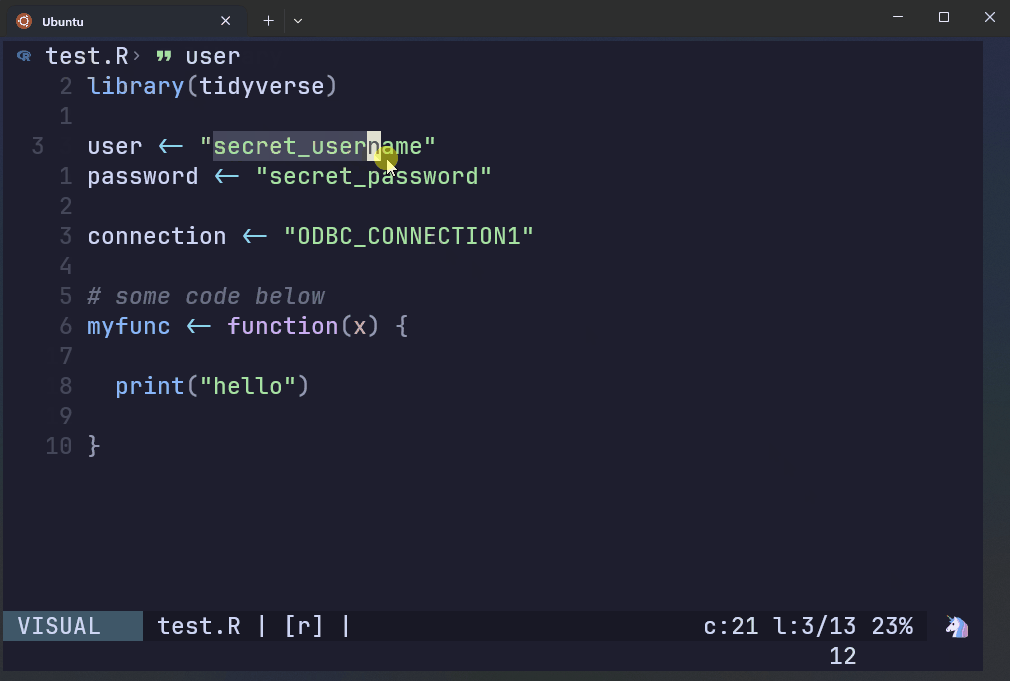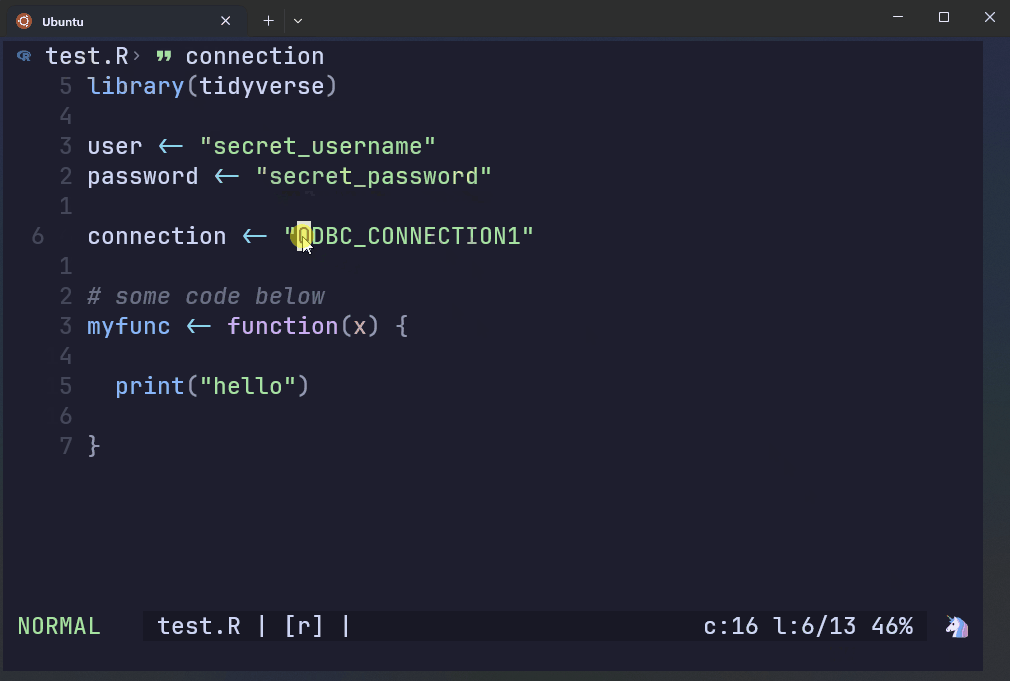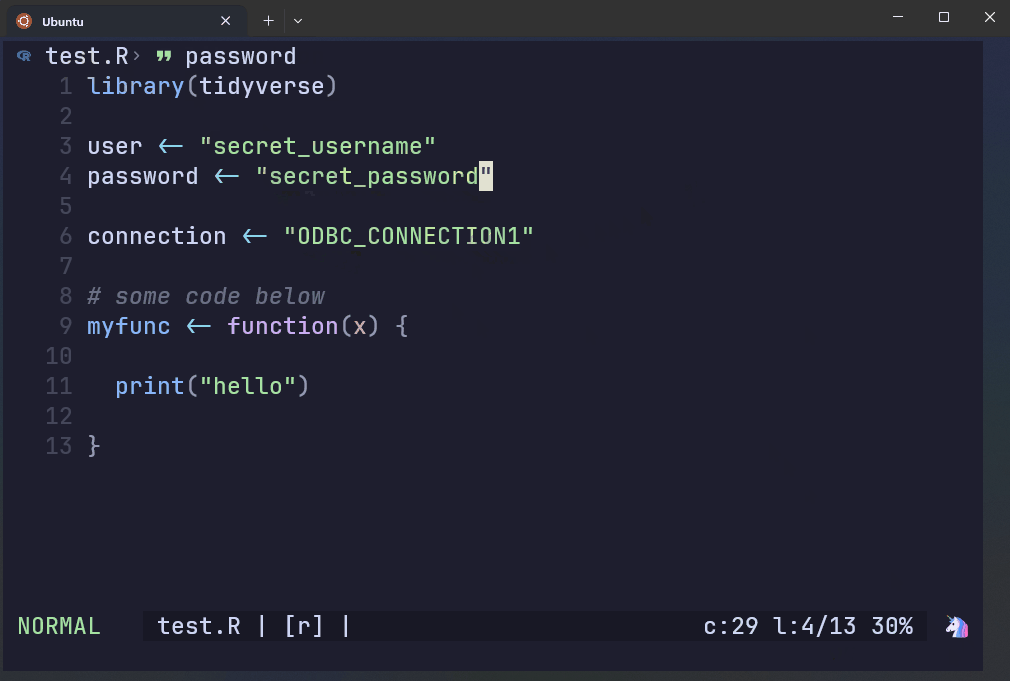
This file contains regular expressions of credentials that are prohibited from being in a remote GitHub repo.
The script to the right has hardcoded prohibited patterns.
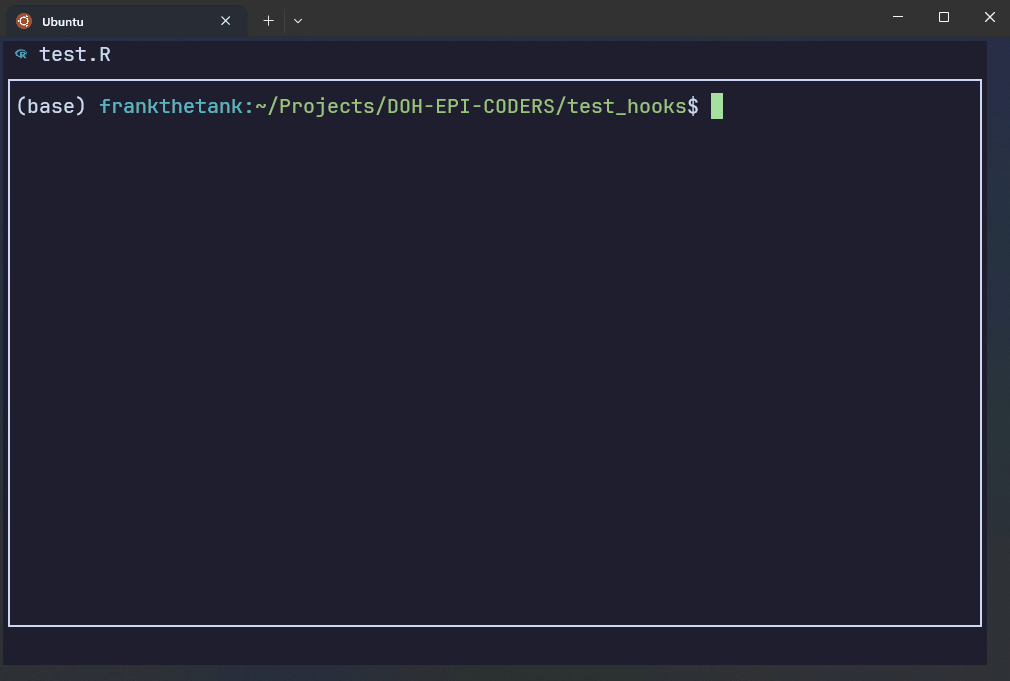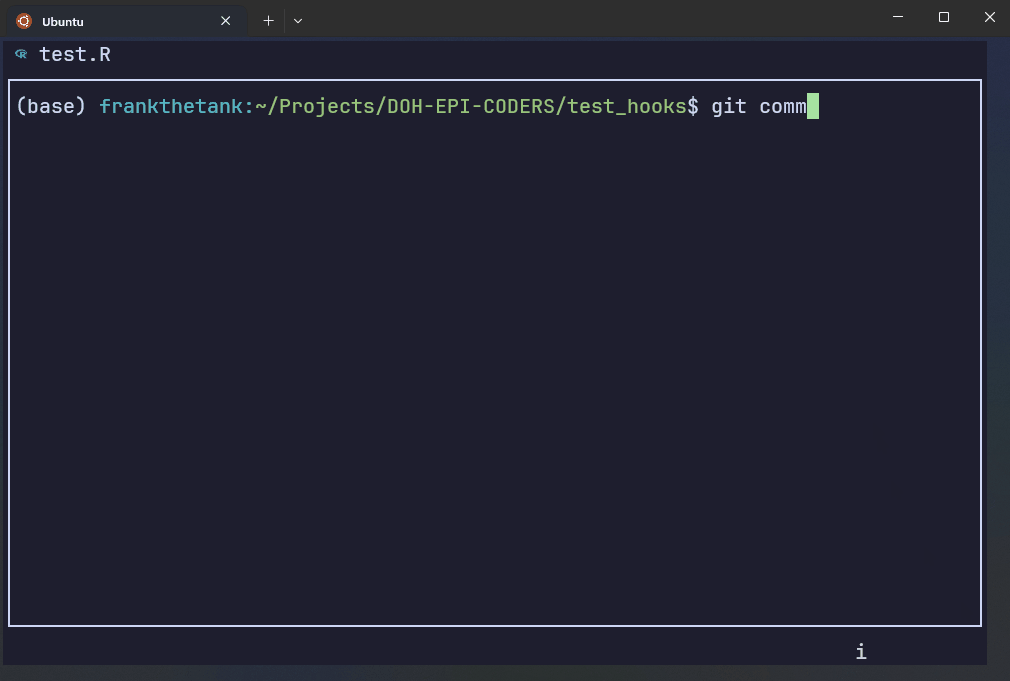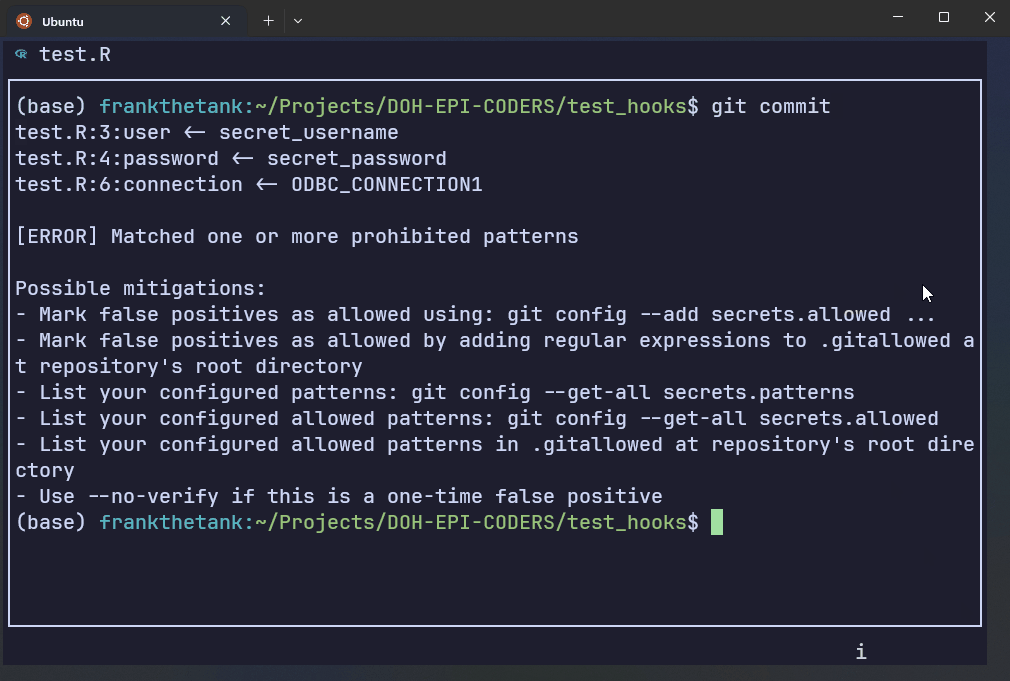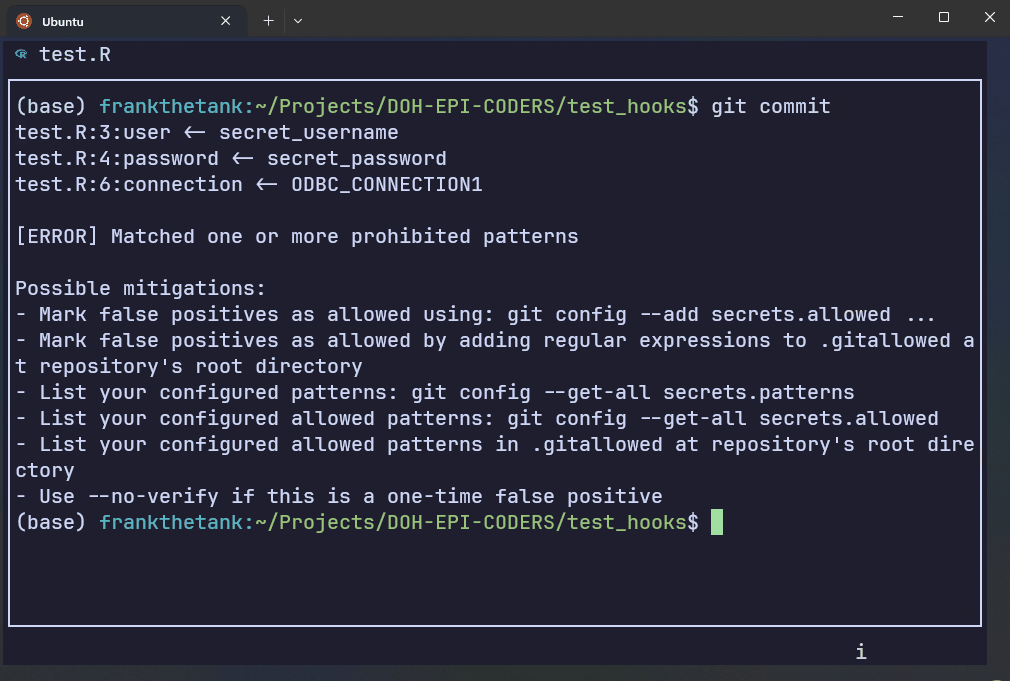
AWS Git Secrets rejects the commit if it detects the patterns found in the secret key file.
The first three lines show the regex patterns that got flagged, along with a warning message. The last chunk gives you instructions on how to handle false positives.
output
test.R:3:user <- secret_username
test.R:4:password <- secret_password
test.R:6:connection <- ODBC_CONNECTION1
[ERROR] Matched one or more prohibited patterns
Possible mitigations:
- Mark false positives as allowed using: git config --add secrets.allowed ...
- Mark false positives as allowed by adding regular expressions to .gitallowed at repository's root directory
- List your configured patterns: git config --get-all secrets.patterns
- List your configured allowed patterns: git config --get-all secrets.allowed
- List your configured allowed patterns in .gitallowed at repository's root directory
- Use --no-verify if this is a one-time false positiveGitHub Pages and Quarto
We can use GitHub Pages to host htmls, and Quarto to develop websites, books, articles, presentations, and reports.
Here’s an example parameterized and automated report.
We can bake our code into the report and produce plots and statistics so that we don’t need to copy and paste screen shots of the plots or manually update numbers everytime we generate the report.
And likewise with text. We don’t need to ‘hardcode’ any text into the document. Notice the statistics written in the text - all of them are ‘written’ using code and can be automatically updated whenever there are changes.
We can bake code into the report and use the outputs in the text.
This code chunk pulls data from a model and assigns it to a variable named wa_prop
And we can use the output wa_prop in the text like this:
And now our code can automatically update the text in the report:
report.qmd
```{r}
# Create a model
model <- multinom(cbind(Alpha, Delta, Omicron) ~ Date,data = variant_data_wide)
wa_prop <- predicted_data %>%
arrange(desc(Date)) %>%
slice(1) %>%
pull(Alpha) %>%
scales::percent(., accuracy = 0.01)
```
## Site Summaries
- Washington State Department of Health - Alpha variant proportion is `{r} wa_prop`
- Georgia Department of Public Health probablity of detection: `{r} ga_prop` and the consensus genomes are uploaded to public repositories like GISAID and GenBank.
- Massachusetts Department of Health prop - `{r} ne_prop`
- Virginia Deparment of Health - `{r} va_prop`
Here’s how parameterized reports work
Start with our .qmd file.
When rendering, we can set the parameter we want.
Quarto will generate a separate output file for each parameter set, with the data filtered according to the specified parameter(s).



but who cares?
I do!
We can use Quarto and GitHub to showcase our work and run code automatically. A GitHub Action can run code conditionally or on a schedule, and GitHub Pages can host the html output of our reports.
examples
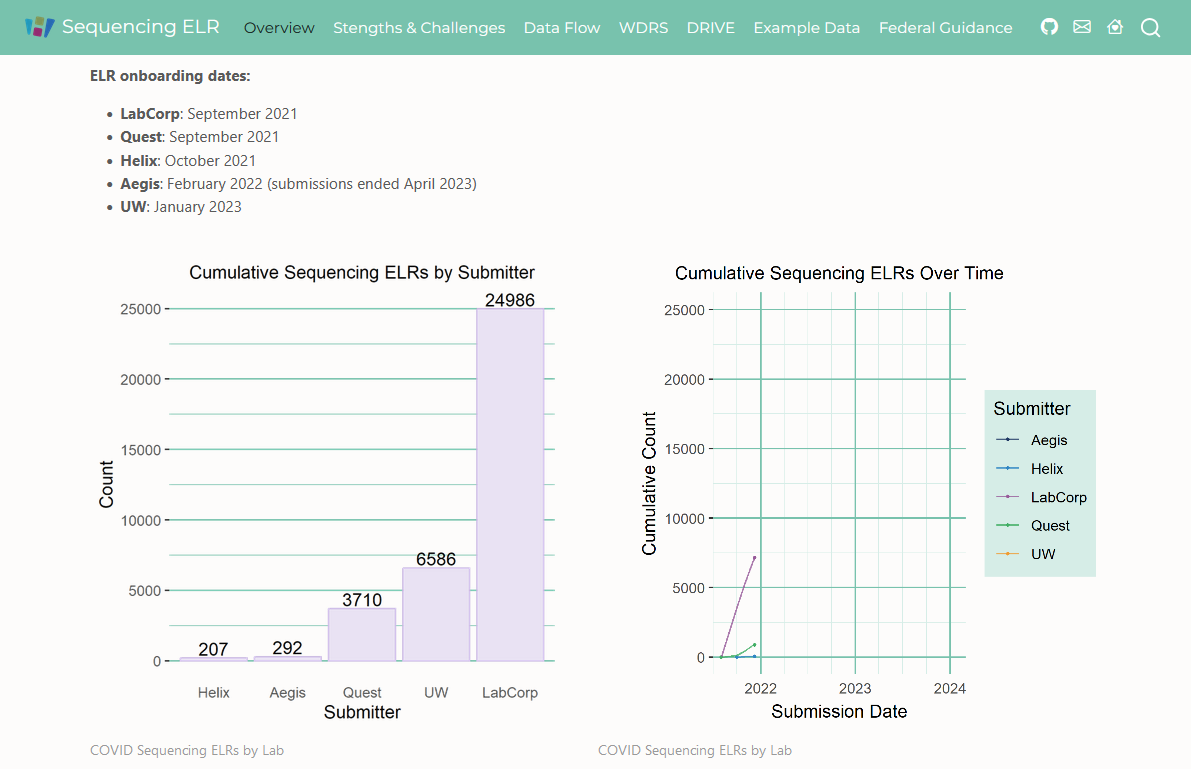
COVID Seq ELR
Author: Philip Crain
Summarize and share COVID-19 Sequencing Metadata ELR data flow at the Washington State Department of Health.
|
This repo provides a high-level description of the Sars-CoV-2 sequencing metadata ELR ingestion process at DOH, from lab submissions to ingestion into the Washington Disease Reporting System where it is linked with epi data. See the GitHub Page for more information |
|
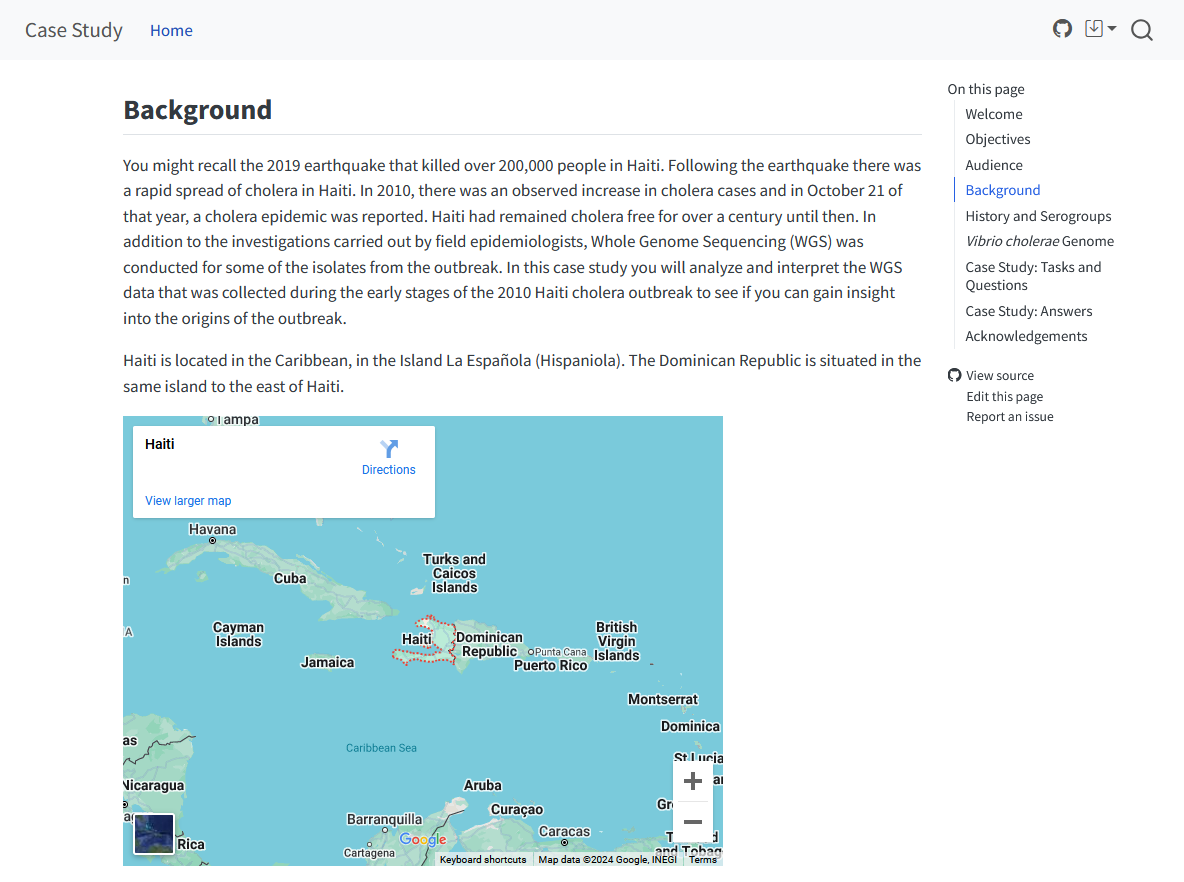
Case Study Vibrio
Author: Marcela Torres
Currently only internal users can see this repo and GitHub Page.
|
This case study is intended for epidemiologists, bioinformaticians, and other public health professionals who are interested in using sequencing data as a way to better understand transmission and links between cases. We provide a couple of options to execute some of the tasks based on different levels of expertise. See GitHub Page for more details. |
|
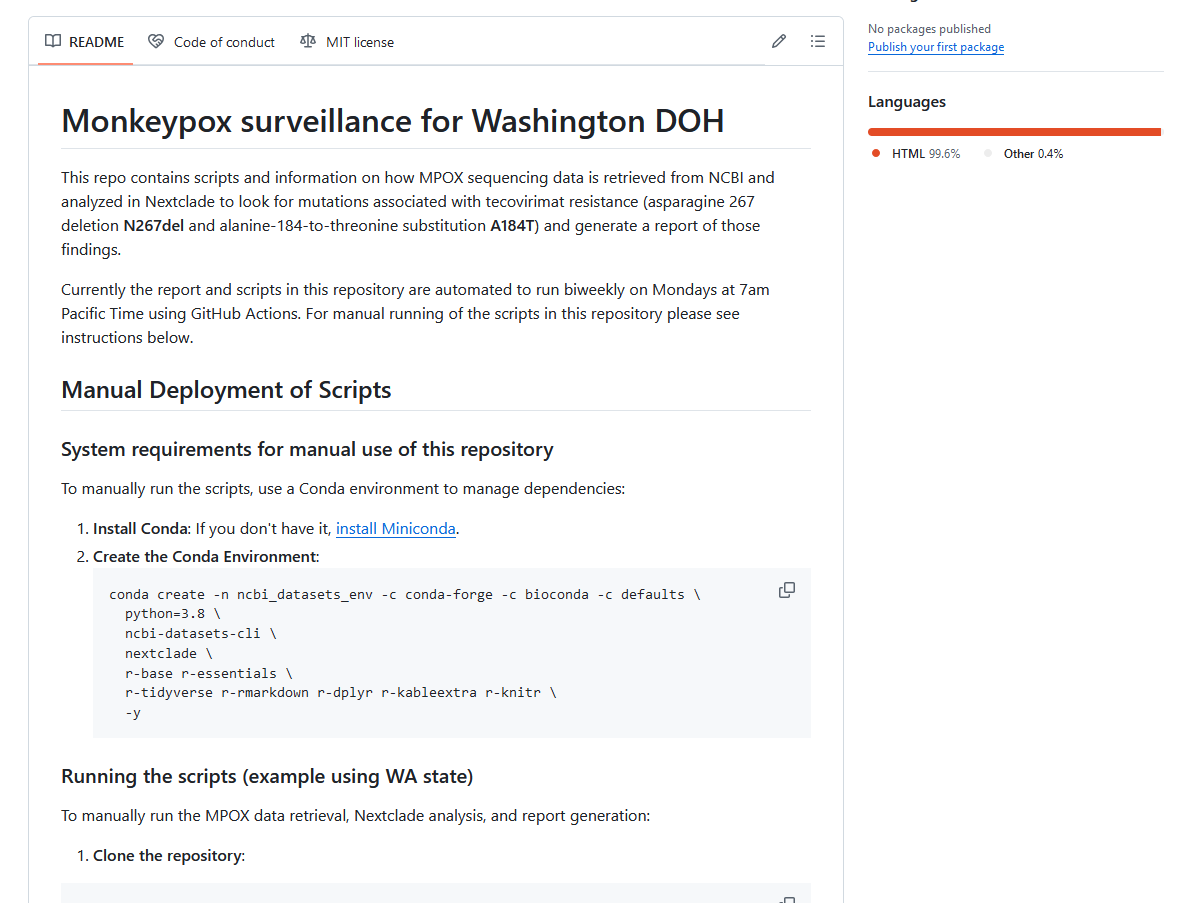
MPOX Surveillance for WA DOH
Author: Pauline Trinh
Currently only internal users can see this repo and GitHub Page.
|
This repo contains scripts and information on how MPOX sequencing data is retrieved from NCBI and analyzed in Nextclade to look for mutations associated with tecovirimat resistance (asparagine 267 deletion N267del and alanine-184-to-threonine substitution A184T) and generate a report of those findings. Currently the report and scripts in this repository are automated to run biweekly on Mondays at 7am Pacific Time using GitHub Actions. For manual running of the scripts in this repository please see instructions below. |
|
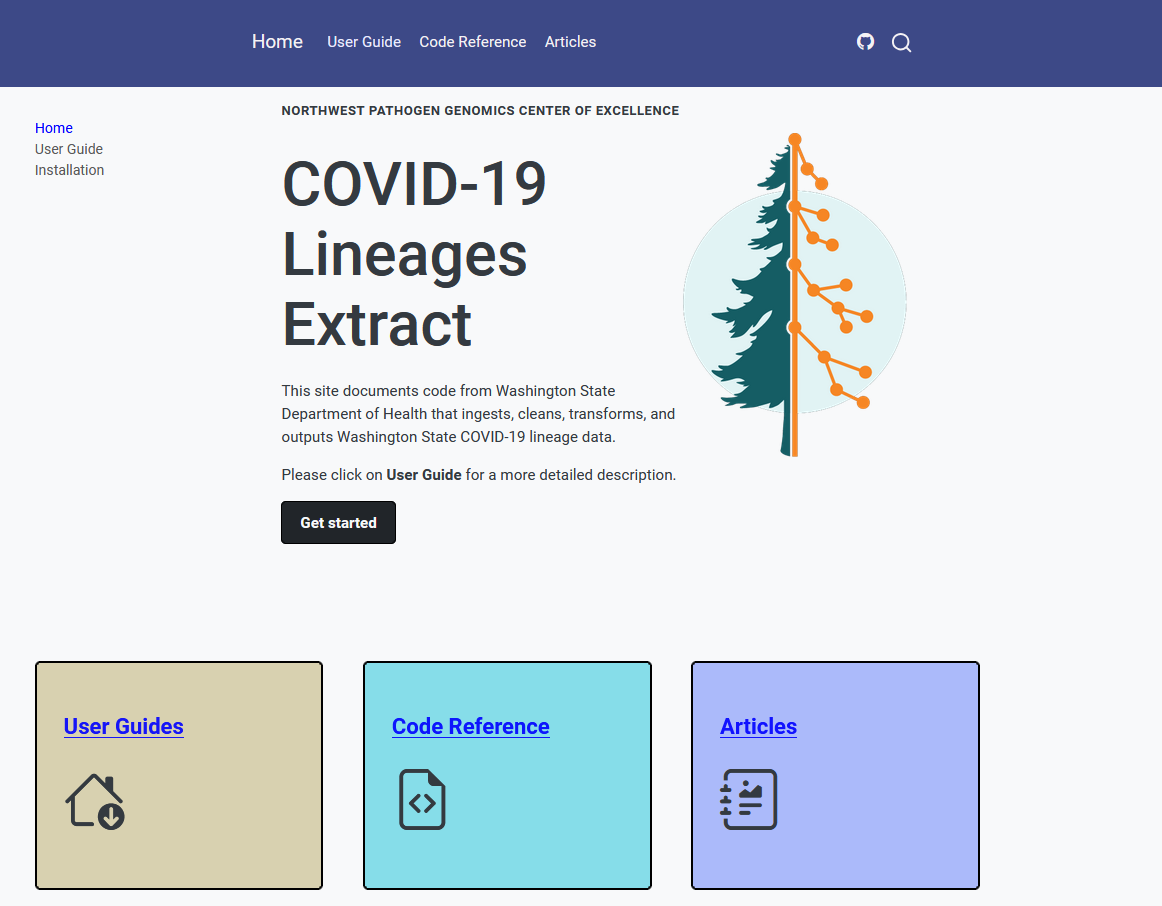
COVID-19 Lineage Classifications
Authors: Lauren Frisbie, Alena Schroeder, Frank Aragona
Create a public lineage classifications dataset. The dataset is maintained by the WA DOH Molecular Epidemiology Program in order to group the lineages for the Sequencing & Variants Report.
|
This repo contains scripts that will pull SARS-COV-2 lineages of interest from CDC’s repo, transform the data for Washington State DOH reporting purposes, and then output the resulting lineage classifications dataset. The dataset will be produced biweekly and can be found in the data folder. See instructions below on how to pull the dataset in R or Python. For more information on how the scripts work, plots, and guides on how to pull data from the repo, please open the github page. |
|
Seq Integration Pipeline
Author: DIQA, MEP, DSSU, evvveryone
Documentation on the first version of the data integration pipeline for sequencing metadata at WA DOH - used during the height of the COVID-19 pandemic.
|
For a more detailed look at the pipeline, please read the manuscript in our github page. The document comes in multiple formats (HTML, PDF and MS Word) and all the main code is documented under the Notebooks tab in the site. There are links to dev containers if you wish to explore the code, although there are no test data sets available at this time. In the future we will push our updated pipelines and test data so that you can explore the code. |

|